Synthetic Dataset Generation Pipeline
An end-to-end pipeline for training a vision model from purely synthetic data, covering dataset generation, training, format conversion, and live deployment to a VPU.
The Problem
Training a computer vision model for quality control typically requires collecting and labelling hundreds of real images of both passing and failing products. For some defect types, gathering enough failure examples from a live production line is slow and impractical.
Synthetic data offers an alternative. Generate as many labelled training images as needed from a 3D scene, with controlled variation built in from the start. The question is whether a model trained entirely on synthetic images generalises to real ones.
The Experiment
The task is binary classification: detect whether a bottle has its cap present or missing. The pipeline runs entirely from a web UI, taking the model from a Blender scene to live inference on dedicated vision hardware.
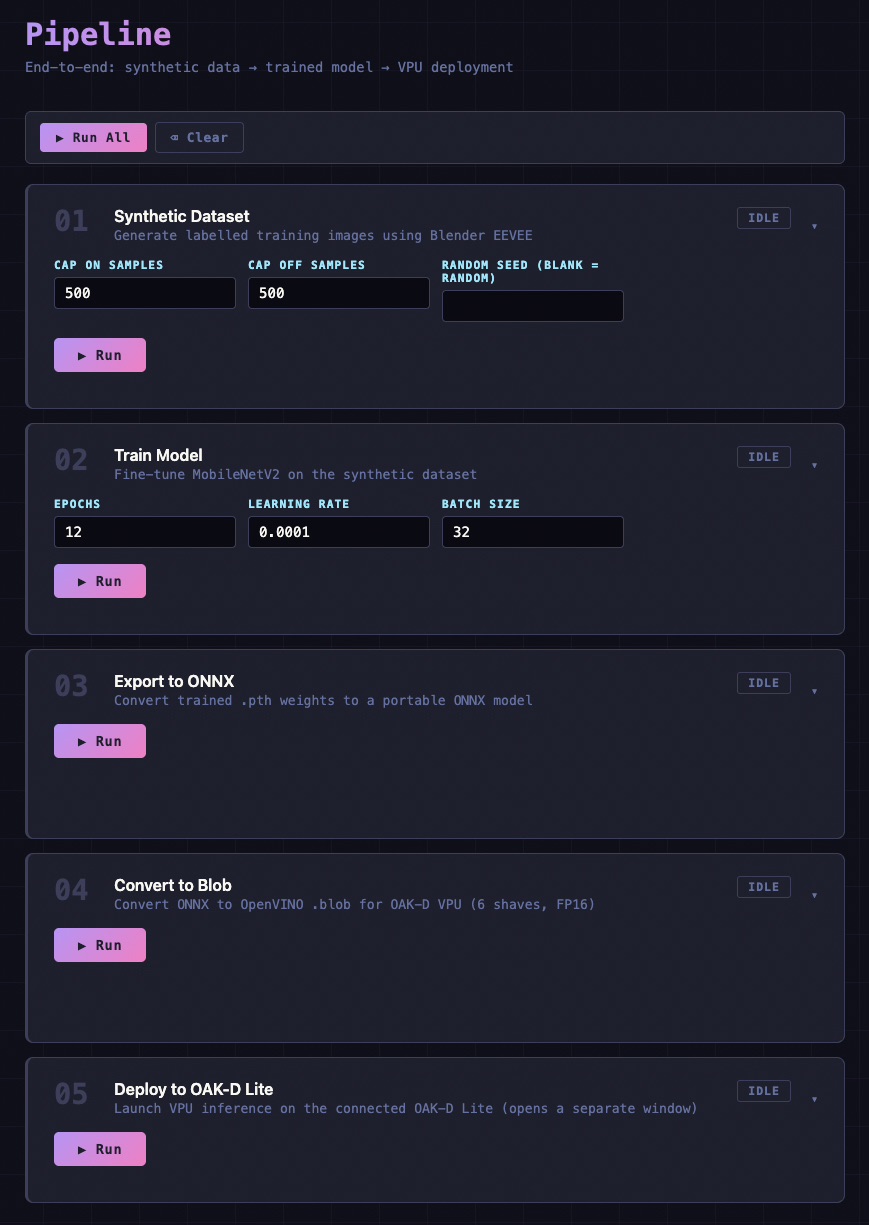
Pipeline UI
The UI is modular and inspired by JupyterLab’s cell-based scripting interface. Each stage is a self-contained card with its own parameter inputs, a run button, and a live output log. Cards check their prerequisites before execution: the training card will not run until a dataset exists; the deployment card will not run until a blob model is present.
This structure makes it straightforward to re-run individual stages without repeating the whole pipeline.
Synthetic Dataset Generation
The 3D scene in Blender contains a bottle with two states: cap on and cap off. A Python script drives Blender headlessly, generating a randomised render for each sample. The parameters varied per image include:
- Camera position, rotation, and field of view
- Key and fill light positions, energy, colour temperature, and size
- Background colour and pattern
Domain randomisation across these parameters means the model encounters a wide spread of appearances during training, which is what allows it to generalise beyond the synthetic distribution.
The default run produces 500 images per class. Sample count and random seed are exposed as parameters in the UI card.
Training
The model is MobileNetV2 pretrained on ImageNet. The classifier head is replaced and fine-tuned on the synthetic dataset. Training completes in minutes on consumer hardware.
The training card accepts epoch count, learning rate, and batch size. A live chart updates after each epoch showing training loss and validation accuracy. The best checkpoint is saved automatically.
The dataset is split 70% for training, 15% for validation, and 15% for test. Augmentations applied during training include random rotation, brightness and contrast variation, horizontal flips, and Gaussian noise.
The target validation accuracy documented for this setup is above 95%.
Export and Deployment
After training, the pipeline offers two export paths.
ONNX converts the PyTorch checkpoint to a portable format. ONNX Runtime runs on CPU without any Python or PyTorch dependency, which makes it practical for web deployment, industrial PCs, and mobile devices.
OpenVINO blob is a compiled format for Intel’s Myriad X VPU. The OAK-D-Lite carries this processor onboard. The blob conversion card calls the blobconverter tool targeting six processor shaves. The deploy card then connects to the OAK-D-Lite over USB and runs the compiled model live at around 24 FPS with around 0.2 ms inference latency.
Performance
| Platform | Inference time | FPS |
|---|---|---|
| Web (CPU, M4 Mac) | ~10 ms | ~40 |
| OAK-D-Lite (Myriad X VPU) | ~0.2 ms | ~24 |
The model generalises to real images of bottles under varied lighting without any real training data.
Status
The pipeline is complete and functional. The trained ONNX and OpenVINO models are included in the repository alongside the Blender scene. The web app exposes a pipeline control view for building and exporting models, and an inspector view for real-time classification via webcam or image upload.